
近期,Soul App AI团队(Soul AI Lab)正式对外开源实时数字人生成模型SoulXFlashTalk,这款模型凭借多项行业首创性能,成为全球首个实现0.87s亚秒级延时、32fps高帧率,并支持超长视频稳定生成的14B参数量数字人大模型。Soul一直将AI技术作为产品创新的核心驱动力,在持续构建AI能力的过程中,始终以技术突破为用户带来更沉浸、更多元的交互体验。此次开源不仅展现了模型在生成速度、画面效果、响应延迟与内容保真度上的全面优势,更重要的是为行业提供了可直接落地商用的解决方案,推动大参数量实时生成式数字人从技术概念走向规模化应用阶段。
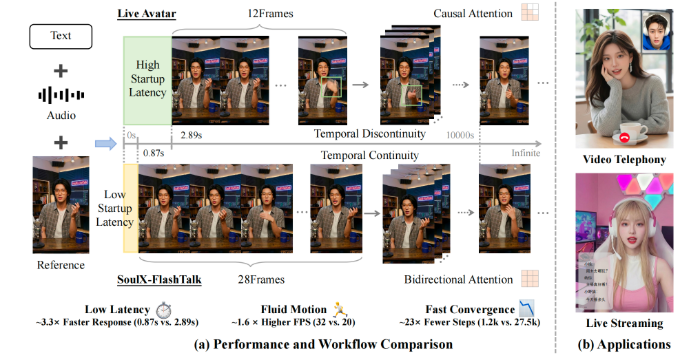
SoulXFlashTalk能够实现极致流畅的实时交互,核心得益于团队打造的全栈加速引擎与深度系统优化。针对8H800节点进行专项设计,模型采用混合序列并行架构,整合Ulysses与Ring Attention机制,让单步推理速度提升约5倍;同时引入针对Hopper架构优化的FlashAttention3算子,通过异步执行进一步将延迟降低20%;3D VAE并行化则借助空间切片并行解码策略,实现处理效率5倍加速;再通过torch.compile完成全流程图融合与内存优化,从系统、算子、模型三个层面实现整体提速。最终,模型将首帧视频输出延时降至0.87s,首次让14B级大模型数字人具备真正意义上的即时反应能力,彻底消除传统大模型生成时的滞后感,可覆盖视频通话、直播弹幕互动、智能客服等全场景实时交互需求,让对话更自然、更流畅。
在生成质量与稳定性方面,SoulXFlashTalk依靠独家自纠正双向蒸馏技术,解决了行业长期存在的画面崩坏、身份漂移、画质下降等痛点。模型搭载多步回溯自纠正机制,能够模拟长序列生成过程中的误差传播并实时修正,主动恢复受损画面特征,如同为AI配备实时校准器。同时,模型完全保留双向注意力机制,使每一帧生成都可同时参考过去与未来上下文,从根源压制身份漂移问题,确保超长直播、长视频生成过程中,人物口型、面部细节与背景环境始终保持一致。此外,模型突破传统数字人仅能对口型的局限,支持音频驱动的全身肢体动态合成,依托14BDiT强大建模能力,精准还原清晰锐利的手部细节,消除畸形与运动模糊,在保持99.22%身份一致性的前提下,实现灵动动作与稳定画面的平衡。
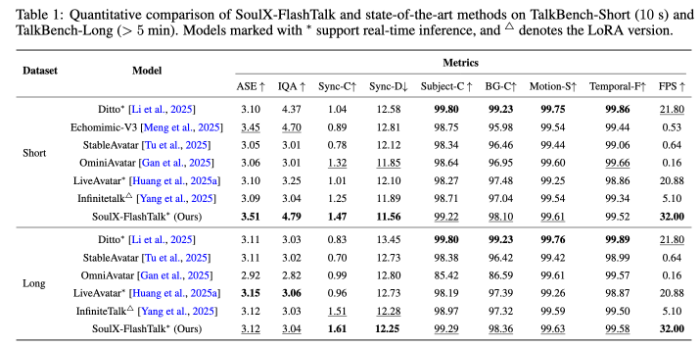
在TalkBenchShort与TalkBenchLong数据集评测中,SoulXFlashTalk各项指标全面领先,短视频以3.51ASE、4.79IQA刷新保真度纪录,长视频SyncC分数达到1.61,且全程保持32fps高吞吐量,远超25fps行业实时标准。该模型可广泛应用于电商7×24小时直播、短视频制作、AI教育、互动NPC、智能客服等场景,解决传统数字人直播卡顿、失真、同步不准等问题。Soul此前开源的SoulXPodcast已收获超3100星标,未来Soul将继续深耕AI交互技术,持续推进开源生态建设,与全球开发者携手推动AI+社交领域持续创新。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
 猜你喜欢
猜你喜欢 “无事不扰,有求必应” 深圳持续优化营商环境
“无事不扰,有求必应” 深圳持续优化营商环境  第32届中国厨师节在福州举办
第32届中国厨师节在福州举办  iPad中国市场份额大跌 华为再夺中国平板第一 暴增21%
iPad中国市场份额大跌 华为再夺中国平板第一 暴增21%  【独家焦点】半场:利雅得胜利3-1多哈国民,科曼双响,德拉克斯勒失点
【独家焦点】半场:利雅得胜利3-1多哈国民,科曼双响,德拉克斯勒失点  半导体板块涨3.46% 利扬芯片涨19.99%居首
半导体板块涨3.46% 利扬芯片涨19.99%居首  南源储能与新源智储签署战略合作协议
南源储能与新源智储签署战略合作协议  三公仔发布儿童用药循证研究成果,七星茶获科学验证护航儿童健康
三公仔发布儿童用药循证研究成果,七星茶获科学验证护航儿童健康  国家开放大学首届新商科创新创业大赛现场赛在北京举办
国家开放大学首届新商科创新创业大赛现场赛在北京举办