
上海财经大学实验中心副主任、金融学院副教授 谢斐
针对大量历史数据采集慢、访问慢,行情实时处理困难等问题,上海财经大学的实验团队尝试搭建一套性能优秀、使用方便的新系统。他们尝试过使用Hadoop、MongoDB等存储数据,但性能始终不能满足需求。2019年由于良好的试用体验,上海财经大学正式采购了DolphinDB时序数据库。本文将由谢斐教授介绍基于DolphinDB的量化高频数据中心系统。
之前上海财经大学使用的系统在数据存储、压缩、调用和运算等方面存在很大问题,需要耗费大量时间进行数据整理。为探索如何存储 CTP 数据,教研团队编写了一套专门存储大量二进制文件的压缩系统,但在使用时发现系统无法处理多来源冗余等问题。
我们在总结经验后建立了系统,可以直接存储 HDF5文件同时实现直接检索,但是该系统响应速度慢、无法动态管理数据。
之后我们尝试了 Hadoop 的 hive 系列,发现该系统不能高效研究结构化数据,需要将结构化问题转化为 MapReduce 脚本后进行处理。
针对持续增长的时序数据,我们希望搭建一套优秀的、使用方便的新系统。
我和研究团队用 Python 编写的基于 DolphinDB 的量化高频数据中心系统总体性能良好,主要解决长时间采集多数据点、实时因子计算和高频数据采集等问题。目前这套系统已经成为教学和科研中的重要工具。接下来本文将从研发背景、数据类型、功能架构、性能测试、选择 DolphinDB 和综上所述等方面对量化高频数据中心系统进行介绍。

研发背景
▪个性化需求:行情厂商标准数据无法提供自定义的 MinBar、HourBar、连续合约及自定义合约等拼接规则,导致量化策略无法实现。
▪历史数据采集现状:数据量大,采集慢,访问慢。采集一年数据可能要耗时几天,无法保证数据没有遗漏。
▪行情实时处理现状:缺乏高效的内存型数据库,无法实时计算因子。
▪自建系统困难:自建数据库采集工具成本高,高频处理系统开发难度高。
数据类型
主要研究 level2 的公开数据,包括每只股票每3秒钟的快照数据,每10毫秒采集多笔的逐笔成交数据和逐笔委托数据。通过数据商获取实时采集数据和盘后数据,数据范围是全市场,包括股票、债券、商品期货、金融期货和期权等。
我们将这两种数据汇总在一起,对数据进行备份、比对,清洗和入库。在目前的研究中,我们入库了2013年到现在的市场全景数据,原始数据总计在 60TB 左右。
功能架构
▪相比传统数据采集方案,本套系统采用性能优秀、可靠性高的架构设计,可以实现高速、自动采集证券或期货的历史数据。
▪借助 AirFlow 工作流平台全自动调度处理金融资产高频历史数据。
▪结合实时行情为多因子量化投资策略等工具提供高效完整的数据计算基础。
▪使用高性能分布式数据库 DolphinDB 进行数据存储。
▪采用 ETL 方案统一数据结构,保证了数据质量和前后依赖关系,同时确保数据的一致性和稳定性。
▪扩展性强,支持 Python、C++、C#、Java 等接口对接第三方系统。
中心功能模块介绍
量化高频数据中心系统的中心功能主要分六大模块:数据采集、数据存储、数据处理、上层应用、状态监控和对外接口。数据中心功能模块的展示图如下:
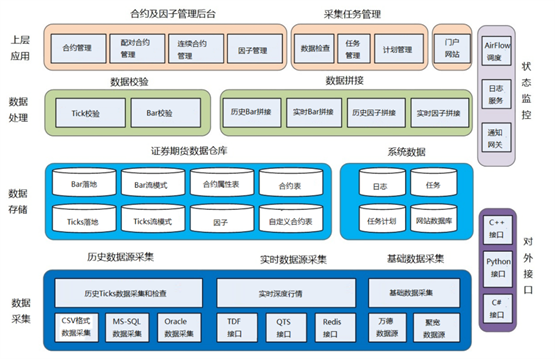
1.数据采集:支持 CSV 文件,系统可以采集 SQL、Orcale、万德、国泰安、通联、聚宽等数据源的历史行情、实时行情及基础数据。
2.数据存储:使用 DolphinDB 存储包括流模式和库模式的 Ticks 和 Bar、合约信息、基类、因子及自定义合约。PostgresSQL 存储数据中心的日志、任务、自动或手动计划及门户前端数据库信息。
3.数据处理:Builder 实现历史及实时 Ticks 拼接 MinBar 和 HourBar,连续合约和配对合约。Validator 校检日线数据和 Tick 数据的准确性。
4.上层应用:主要分管理后台和采集任务管理。管理后台提供合约管理功能,包括查询、自定义合约、连续合约和因子等。采集任务管理包括自动或手动采集管理数据,计划任务管理及数据完整性检查。
5.状态应用:提供 AirFlow 调度平台的运行状态、日志服务及通知网关。
6.对外接口:支持 Python,C++,C#等 API 接口。
架构介绍
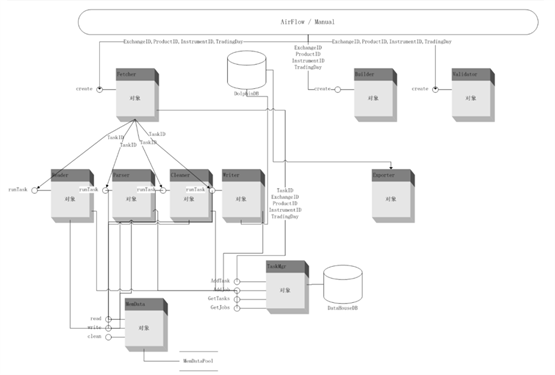
数据中心使用 AirFlow 通过 TaskID、JobID 调度整个系统的运行顺序和状态。TaskID 和 JobID 可以保证数据采集的完整性和出错重做机制。将采集的数据写入 DolphinDB 集群和内存中以方便调用,同时对数据进行拼接和校验。系统提供 Exporter 输出接口,通过 Manager 后台对整体进行配置和管理。数据中心系统的架构图如下:
性能测试
分别测试同等硬件条件下,采用 MongoDB 和 DolphinDB 两种数据库存储数据的系统采集入库上海期货交易所一周 Tick 数据(712万条)的性能。具体测试数据如下:
DolphinDB 写入速度超过 MongoDB近8倍

之前使用 MongoDB 入库一周 tick 级的数据需要1000秒钟左右。重构系统后使用 DolphinDB 多线程采集宏汇的数据源,在保证整个原始任务的逻辑关系的基础上进行入库保存。因为 DolphinDB 目前还不支持同区多线程写入,所以我根据 DolphinDB 的特性编写了入库程序进行任务分派,入库上海期货交易所一周 tick 级的数据仅需要120秒钟左右。相比 MongoDB,DolphinDB 的速度提升效果是比较明显的,足以支持我们下决心采购这套商业系统。我们在使用其他开源系统时,比如做大数据并行时遇到过不少问题,但是无法及时得到解决。DolphinDB 的技术支持团队在数据入库和分区等方面为我们提供了很多方案, 可以保证及时、专业的技术支持。
读取性能测试
用基于 DolphinDB 研发的量化高频数据中心系统读取深市某股票一年数据,具体测试结果如下:
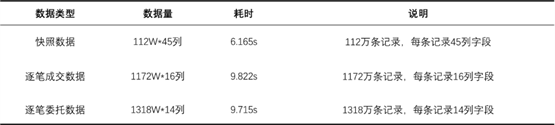
之前是在每台机器两块硬盘的情况下进行测试,将所有数据放入一个库中进行处理。现在根据 DolphinDB 技术专家的建议,提出对数据进行分区分表的新方案。目前的实际速度要比表中的速度更加快。
实时数据计算性能
测试系统实时计算的性能,具体测试结果如下:

借助 DolphinDB 专有的流计算引擎,在实际使用中可以实现10毫秒内因子计算,比如获取行情,将行情数据转换成计算因子如均线、K 线等然后进行存储,同时按照需求订阅需要的多个合约和因子数据。
选择 DolphinDB
首先,DolphinDB 的性能很好。我们在2018年采购了5台256GB 内存、十几 TB 硬盘的服务器和一套服务系统,主要研究市场微观结构,比如研究融资融券,思考交易如何影响市场。再比如识别、探究订单户数据时,数据量大概在每天八千万到一亿条。之前我们每天要花大概3个小时去处理数据,修改数据非常困难。现在使用 DolphinDB 提供的一站式服务只需要花30分钟即可完成处理,使用变得非常便捷。
在做高频量化交易时,模型和参数的迭代是很快的,选取以周为单位、一年的历史数据已经在单机上占用了很大内存。我们之前使用 512GB 内存的服务器研究有关市场结构的课题,想以整个市场截面查询很多证券的操作情况,需要的数据量大概在 500GB 左右,经常会超限。
所以我们需要做一套分布式的处理系统,这对我们团队的代码编写和程序设计能力有很高的要求。由于我们不是并行处理方面的专家,我会用 Python 或者 MATLAB 在多节点中分开计算,但面对数据在500GB 以上的场景时还是比较力不从心,需要用小的截面反复去做,然后统计所有截面数据寻找相关性。这块工作的强度很大,并且需要花费不少时间。
但是在使用 DolphinDB 后,研究变得非常方便。所有节点的总内存是1.0TB,DolphinDB 处理这个规模数量级的数据是比较稳定快速的,可以自动进行分布式计算。
其次,DolphinDB 上手快,学习门槛低。因为 DolphinDB 的脚本语言是类 SQL 的逻辑,我会安排学生先学习SQL,学会用 SQL 读取数据后,再学习使用 DolphinDB Script 进行复杂操作。由于学生都有 Python 基础,在学习SQL 后大概一个礼拜就能上手 DolphinDB。教学内容包括数据导入、查询、策略回测和 DolphinDB 的一些特性操作如表拼接等。对于学金融和量化投资的学生来说,DolphinDB 是一套上手容易、使用友好的数据库。
综上所述
基于 DolphinDB 研发的量化高频数据中心系统很好地满足了每天进行实时策略回测、模拟交易等业务的需求。不管是学校的科研项目,还是与券商、基金公司等合作的项目,尤其在高频量化场景等重要场景中,都会使用这套系统来开发相应的策略和应用。
目前 DolphinDB 已经正式成为我的量化投资和程序化交易课程中非常重要的一部分。我认为 DolphinDB 好学、好用、好维护,非常适合IT力量薄弱的机构。我们与 DolphinDB 的合作是互相尊重、友好积极的,诚挚希望未来可以有更多的合作机会。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
 猜你喜欢
猜你喜欢 诚志股份筹划分拆子公司北京
诚志股份筹划分拆子公司北京  CPI高于预期!美国通胀继续
CPI高于预期!美国通胀继续  今后五年北京经济总量将突破
今后五年北京经济总量将突破  中金公司拟配股募资不超过27
中金公司拟配股募资不超过27  上市银行资产质量保持稳定
上市银行资产质量保持稳定  趋势|从德国,到巴西,再到
趋势|从德国,到巴西,再到  8月库存预警指数表现稳定
8月库存预警指数表现稳定 



